Assembleur : calculs en virgule flottante
Changement de méthodes et reprise après une longue pause. Je vous propose aujourd'hui de faire quelque chose d'infiniment gratifiant : faire la nique à GCC. En langage soutenu, nous dirons que nous allons faire plus rapide que la fonction C générée par GCC.
De GCC. Si. C'est fou. De NASM aussi. Et d'un éditeur. Et du C. Le tout sous un système POSIX sur architecture amd64.
Vous n'allez pas le croire : si. On se propose de faire la somme de 2 vecteurs de double, opération courante au possible.
Flottante. C'est quand même dingue de devoir répéter à l'écrit. Mais expliquons :
Lorsque l'informatique est née, on travaillait en nombres entiers, comme les enfants au cours élémentaire. Très vite, genre après le déjeuner, on s'est aperçu qu'une bombe de 1,2 mégatonnes n'est ni à 1 mégatonne ni à 2 : les entiers sont peu adaptés au calcul scientifique. Alors on a travaillé en virgule fixe. Travailler en virgule fixe, ça signifie qu'on travaille avec des nombres entiers, et qu'on est d'accord pour, à la fin, mettre la virgule à une position fixée à l'avance. La virgule est fixe, paf !, l'appellation "virgule fixe" est née. On est très imaginatifs sur les noms des choses, en sciences. Bref, on dit qu'on travaille en dixièmes de mégatonnes, du coup la bombe fait 12 * 0,1 mégatonnes, et on retombe sur des entiers. Et on peut utiliser l'arithmétique des entiers, qui est la seule disponible sur les processeurs standard.
Le truc naze avec la virgule fixe, c'est que un million et un millionième sont traités de la même façon : on se balade donc avec une dizaine de zéros qui ne servent à rien. Alors on a conçu un processeur qui calcule en virgule flottante. Ce n'est pas un processeur standard, parce que les opérations sont différentes, les bits n'ont pas la même signification. La virgule flottante n'est pas fixe, d'où le nom. Oui, je sais, où vont-ils chercher tout cela ? En gros et à peu près, on découpe le nombre en deux parties : les chiffres d'un côté et la position de la virgule de l'autre. Wikipédia est ton ami, il faut bien que mes dons servent à quelque chose. L'important n'est pas là, l'important est que ce n'est ni les mêmes instructions, ni le même processeur qu'on utilise quand on fait du calcul sur des réels, et que c'est d'origine historique. Et comme c'est historique, ça a évolué, et c'est un peu des Jenga sur du Légo.
Donc, il y avait une bonne façon de faire du calcul en virgule flottante qu'on n'utilise plus depuis si longtemps que l'évoquer aujourd'hui devrait être sa seule sortie des listings d'instructions machine. Maintenant, il faut utiliser SSE.
Deux sujets dans ce projettounet (c'est un tout petit projet, il est mignon : c'est un projettounet). Le calcul en virgule flottante et l'appel d'une fonction assembleur dans un programme C.
- C et NASM
- remplit aléatoirement un vecteur de taille impaire de valeurs pseudo-aléatoires comprises entre 0 et 1,
- met un autre vecteur de même taille à zéro. Ce vecteur sera changé par l'appel aux fonctions de somme,
- appelle, en boucle, les deux fonctions déclarées, l'une après l'autre,
- affiche une partie des résultats et les temps mesurés.
- NASM et double
L'idée va être de comparer les temps d'exécution de fonctions au fonctionnement identique mais codées différemment. Commençons par le code C :
#include#include #include void sommeVect(int, double *, double *); /*========== partie relative a la mesure du temps ===========*/ #include #include typedef struct tms sTms; typedef struct{ int debut,fin; sTms sdebut, sfin; }temps_exec; /*========== partie relative a la mesure du temps ===========*/ void temp(temps_exec *tmps){ printf("temps réel :\t %d ms\ntemps utilisateur :\t %ld ms\ntemps system :\t %ld ms\n", tmps->fin - tmps->debut, tmps->sfin.tms_utime - tmps->sdebut.tms_utime, tmps->sfin.tms_stime - tmps->sdebut.tms_stime); } void sommeVect2(int nb, double *a, double *b) { int i = 0; for (; i < nb; i++) { a[i] += b[i]; } } int main() { srand(time(NULL)); const int nb = 1000003; const int nbReps = 10000; int i = 0; double * a = (double *)malloc(nb*sizeof(double)); double * b = (double *)malloc(nb*sizeof(double)); for (i = 0;i < nb; i++) { b[i] = rand()/(double)RAND_MAX; } memset(a, 0, nb*sizeof(double)); temps_exec temps; int top = sysconf(_SC_CLK_TCK); /* recupere le nombre de tips seconde */ temps.debut = times(&temps.sdebut); for (i = 0;i < nbReps; i++) { sommeVect(nb, a, b); } temps.fin = times(&temps.sfin); for (i = 0;i < 3; i++) { printf("%d * %f = %f\n", nbReps, b[i], a[i]); } temp(&temps); memset(a, 0, nb*sizeof(double)); temps.debut = times(&temps.sdebut); for (i = 0;i < nbReps; i++) { sommeVect2(nb, a, b); } temps.fin = times(&temps.sfin); temp(&temps); for (i = 0;i < 3; i++) { printf("%d * %f = %f\n", nbReps, b[i], a[i]); } free(a); free(b); return 0; }
Alors, je vous explique l'idée : on déclare une fonction qui n'est pas codée ici, hé non. Comme ça le compilateur la cherchera partout, ha, ha, ha (en fait non, il la cherchera dans des endroits spécifiques). Ensuite on code une fonction qui calcule effectivement, en C, la somme de deux vecteurs. Le code est d'un compliqué. Après ça, on trouve des fonctions de mesure du temps écoulé que j'ai, éhonté, copié de l'internet. Et enfin le main, qui :
Dans ce fichier C, on n'a pas dit comment trouver la fonction qu'on va faire en assembleur. C'est une déclaration de fonction normale, pas de blague particulière, nada. Pour faire le lien entre C et NASM, il faut simplement savoir comment se passent les paramètres des fonctions, et c'est tout. Et ça se passe comme ça, mon petit bonhomme : en ce qui nous concerne, les pointeurs et entiers (qui sont la même chose) sont passés dans cet ordre : RDI, RSI, RDX, RCX, R8 et R9 et à partir du septième on lit la pile. Les paramètres en virgule flottante sont passés dans cet ordre : XMM0, XMM1, XMM2, XMM3, XMM4, XMM5, XMM6 et XMM7, puis la pile. Après un appel de fonction l'appelant s'attend à avoir perdu tous ses registres sauf : RBP, RBX et de R12 à R15. On peut donc modifier allègrement : RAX, RCX, RDX, de R8 à R11, tous les XMM et leurs copains oubliés. Et c'est comme ça ici et c'est pareil ailleurs, tout ce que la terre a fait de meill... pardon. Et c'est comme ça sous Linux et c'est différent sous Windows et je suppose que c'est encore une autre méthode sous Mac, y'a pas de raison qu'ils aient pondu le même format qu'un des deux autres. C'est pour ça qu'on développe ici sous un OS Posix. Avec cela en tête, le compilo saura faire le lien entre C et ASM.
L'idée de base : faire la somme de plusieurs double. C'est important, le plusieurs. Un ordinateur calcule, et calcule beaucoup. Autant que ses calculs, il les calcule franchement. Donc, non, on n'utilise pas un Quad-Core Trio biréfringéré à cache positronique multicouche pour calculer une somme, tout comme on n'utilise pas une pelleteuse pour planter une salade. On l'utilise pour calculer une tétra-chiée de sommes.
Donc, on a des instructions qui calculent plusieurs sommes de nombres à virgule flottante d'un coup. Deux, en l'occurence. On part du principe que les départs des tableaux sont alignés sur 128 bits. Si ce n'est pas le cas, ma foi, on verra plus tard. On lit donc d'un coup deux double (2 * 64 bits, soit un Octuple Mot, OWord) dans chaque vecteur, et on calcule la somme.
Voyons le code NASM :
bits 64 ;Yeah, baby, 64 bits, c'est plus du p'tit 32, c'est du moderne, du nouveau, du balèze global sommeVect ;Ici, mon jeune ami, on dit que le label sommeVect est accessible à qui veut l'appeler. section .text align=16 ;Oui, une section .text. Admettons sommeVect: ;Le point d'entrée de la fonction qui va manger du GCC xor r8, r8 ;Une MàZ d'un registre qui va se souvenir de la parité du nombre d'éléments à sommer. Ah ben oui, on fait 2 sommes d'un coup, d'accord, mais si c'est impair ? mov rcx, rdi ;Nombre d'éléments à sommer mis dans RCX parce que c'est le registre compteur shr rcx, 1 ;qu'on divise par 2, parce qu'on va les sommer par 2 jnc .lecture ;Et si la retenue (carry flag) est posée, la taille est impaire inc r8 ;On se souvient que c'est impair pour plus tard .lecture: mov rax, rsi ;vecteur accumulateur. RDX contient le vecteur Ãf ajouter .somme: movapd xmm0, oword [rax];On met dans un registre du processeur à virgule flottante 2 double movapd xmm1, oword [rdx];Idem pour l'autre addpd xmm0, xmm1 ;L'instruction de la somme movntpd oword [rax], xmm0;On stocke le résultat dans l'accumulateur add rax, 16 ;On passe à la paire de double suivante add rdx, 16 ; loop .somme ;Et on boucle sur RCX cmp r8, 0 ;Si la taille des vecteurs est paire jz .retour ;Merci, c'est fini. Sinon, c'est impair. movsd xmm0, qword [rax] ;On met dans un registre du processeur à virgule flottante le dernier double movsd xmm1, qword [rdx] ;Idem addsd xmm0, xmm1 ;On fait une seule somme movsd qword [rax], xmm0 ;Et donc une seule sauvegarde. Et fin. .retour: ret
Pour compiler et exécuter cela, je vous ai fait un script :
#!/bin/bash nasm -f elf64 -o sommeDouble.o sommeDouble.asm gcc -o sommeDouble testSommeDouble.c sommeDouble.o -O3 ./sommeDouble
Notez que je ne le fais pas comme un goret : je donne toutes ses chances à gcc avec un O3. Il ne s'agit pas de comparer un temps en debug avec un temps optimisé, on joue cartes sur table, ici, jusqu'à preuve du contraire.
Et si tout s'est bien passé, vous devez obtenir des additions justes et. Et. Les premiers temps d'exécution plus courts que les seconds. GCC doit être plus lent que nous. Si ça c'est pas la classe.
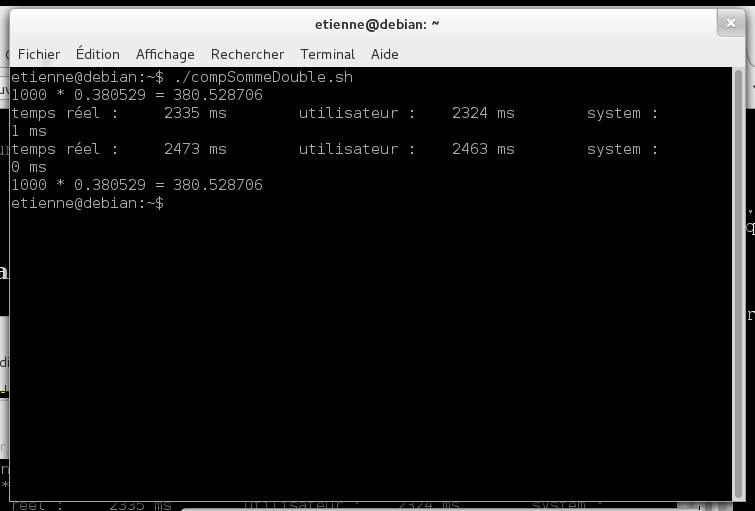
Insérer ici une image de champagne qui pète, de feu d'artifice qui chatoie et de conquistador qui conquiert.
Calmons néanmoins nos justes ardeurs. Nous n'avons pas traité le cas d'une adresse de départ non alignée. On verra plus tard, il faut que je me renseigne sur l'opportunité de ce traitement. Ensuite, peut-être que gcc est mal configuré.
Reprenons notre enthousiasme. Les ms de différence montrent au moins une chose : non, les compilateurs modernes ne génèrent pas du meilleur code assembleur qu'un humain, même pour des choses simples. La sortie assembleur de gcc montre qu'il fait quelque chose de lourd et compliqué pour, au final, quelque chose de tout bête.
Néanmoins, c'est bien beau, mais pratiquement, je ne sais que faire de cette performance. C'est dommage de la laisser moisir ici, alors je demande de l'aide. Contactez-moi pour faire avancer la vitesse de calcul.