Assembleur : passage à MASM, Visual Studio et AVX
Chers non-lecteurs (depuis 5 ans que je n'ai pas posté, je n'ai plus de lecteurs, que des non-lecteurs donc). Chers non-lecteurs (mais si vous lisez ceci, vous devenez lecteur et cher à mon coeur). Cher non-lecteur, disais-je donc avant d'être interrompu par moi-même, de longues années ont coulé sous les ponts depuis notre dernière rencontre. Et les choses ont évolué.
Tout d'abord et en premier lieu, votre serviteur a vécu d'innombrables vicissitudes qui l'ont conduit d'un système stable et performant à un système au comportement aléatoire et aux plantages intempestifs. Oui, je suis passé de Debian à Windows. A contrecoeur, je tiens à le préciser. Mais, si je suis passé du côté obscur de la force en ce qui concerne le système d'exploitation, je suis passé d'un poussif CPU SSE à un fulgurant AVX, ce qui me plonge dans d'insondables abîmes de perplexité, que nous allons voir dans ce chapitre.
Ensuite, je suis passé de YASM à MASM pour la bête raison que c'est fourni avec Visual Studio et que ça fait le job. Il y a 3-4 modifs à faire, rien de bien méchant.
Enfin, les compilateurs se sont sérieusement améliorés, et pour une raison que j'ignore, les anciennes instructions SSE sont plus rapides que les nouvelles AVX, mais nous y reviendrons.
Donc on change tout. Nous avons besoin d'un microprocesseur à même de comprendre les instructions AVX. Pour vérifier la compatibilité de votre bête de course, CPU-Z publie un très beau CPUInfo. Vous allez là https://www.cpuid.com/softwares/cpu-z.html, vous téléchargez l'installeur, tout ça,vous exécutez le logiciel, et vous devriez avoir quelque chose qui ressemble à ça :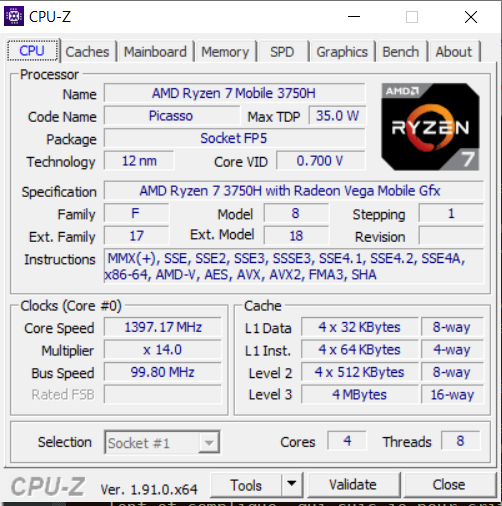
A ma grande rage et mon léger désespoir, ce que nous allons voir dans ce chapitre n'aura pas d'utilité certaine, à part peut-être pour certaines instructions sur certaines machines.
Je ne sais pas ce qui s'est passé dans le monde du silicium, peut-être que des fonctions sont devenues désuètes, mais les versions codées du sinus et du cosinus sont parfois plus rapides que leurs version hardware. Les temps ont bien changé.
- Du sinus
- Des opérations algébriques
- Du produit scalaire
- Résultats.
Comme les nouveaux jeux d'instruction n'incluent toujours pas de fonction trigonométrique, nous allons utiliser le code précédent, basé sur le coprocesseur arithmétique.
PUBLIC sinv_asm
sinv_asm PROC
sinus:
fld qword PTR [rdx - 8 + 8 * rcx] ;On met dans un registre du processeur à virgule flottante un double
fsin
fstp qword PTR [rdx - 8 + 8 * rcx] ;On stocke le résultat
loop sinus ;Et on boucle sur RCX
ret
sinv_asm ENDP
PUBLIC cosv_asm
cosv_asm PROC
cosinus:
fld qword PTR [rdx - 8 + 8 * rcx] ;On met dans un registre du processeur à virgule flottante un double
fcos
fstp qword PTR [rdx - 8 + 8 * rcx] ;On stocke le résultat
loop cosinus ;Et on boucle sur RCX
ret
cosv_asm ENDP
PUBLIC tanv_asm
tanv_asm PROC
tangente:
fld qword PTR [rdx - 8 + 8 * rcx] ;On met dans un registre du processeur à virgule flottante un double
fptan
fstp qword PTR [rdx - 8 + 8 * rcx] ;On stocke le résultat
loop tangente ;Et on boucle sur RCX
ret
tanv_asm ENDP
Peu de changements, juste quelques adaptations nécessaires à MASM. Primo, la directive PUBLIC, qui précise que la fonction en paramètre sera exportée. Secundo, la directive PROC pour indiquer à MASM qu'il s'agit d'une fonction. Ou d'une procédure. La différence n'est plus bien claire maintenant, mais à l'origine, les fonctions renvoyaient des valeurs contrairement aux procédures. Et enfin la directive ENDP qui signale la fin de la procédure.
Petit détail qui a son importance : la procédure d'appel des fonctions n'est pas la même que précédemment, sous Linux. Les 4 premiers paramètres entiers sont maintenant passés par RCX, RDX, R8 et R9, tandis que les 4 premiers paramètres en virgule flottante sont passés par XMM0, 1, 2 et 3.
Avant toute chose, nous allons utiliser des instructions traitant 32 octets à la file. Or, la fonction malloc n'aligne les octets que sur 16 octets. Nous allons donc appeler un malloc spécial : _aligned_malloc, qui prend deux paramètres : en premier, l'espace à allouer, et en second, le multiple de 2 sur lequel on doit s'aligner. Bien évidemment, c'est une fonction microsoft, et donc elle n'existe pas pour Linux. Néanmoins, il existe une fonction standard qui a le même comportement, mais apparemment microsoft ne l'a pas implémentée. Il s'agit de la fonction aligned_alloc(size_t alignment, size_t size). Chose à savoir : tout ce qui a été alloué avec _aligned_malloc doit être libéré avec _aligned_free.
Voici donc les 4 opérations usuelles en AVX :
PUBLIC sumv_asm
sumv_asm PROC
shr rcx, 2
somme:
vmovapd ymm0, YMMWORD PTR [r8]
vaddpd ymm0, ymm0, YMMWORD PTR [rdx]
vmovntpd YMMWORD PTR [rdx], ymm0
add rdx, 32
add r8, 32
loop somme
retour:
ret
sumv_asm ENDP
PUBLIC subv_asm
subv_asm PROC
shr rcx, 2
somme:
vmovapd ymm0, YMMWORD PTR [rdx]
vsubpd ymm0, ymm0, YMMWORD PTR [r8]
vmovntpd YMMWORD PTR [rdx], ymm0
add rdx, 32
add r8, 32
loop somme
retour:
ret
subv_asm ENDP
PUBLIC divv_asm
divv_asm PROC
shr rcx, 2
division:
vmovapd ymm0, YMMWORD PTR [rdx]
vdivpd ymm0, ymm0, YMMWORD PTR [r8]
vmovntpd YMMWORD PTR [rdx], ymm0
add rdx, 32
add r8, 32
loop division
ret
divv_asm ENDP
PUBLIC mulv_asm
mulv_asm PROC
shr rcx, 2
mult:
vmovapd ymm0, YMMWORD PTR [rax]
vmulpd ymm0, ymm0, YMMWORD PTR [r8]
vmovntpd YMMWORD PTR [rdx], ymm0
add rdx, 32
add r8, 32
loop mult
ret
mulv_asm ENDP
Mais que voyons-nous là ? Quelle est cette curiosité ? Notre instruction MOVAPD (MOVe Aligned Packed Double) prend maintenant un préfixe V ? et quel est ce registre YMM0 ? En AVX, on a créé une extension des registres XMM vus dans les chapitres précédents : ce sont les registres YMM. Ils se superposent aux registres XMM de la même façon que le registre RAX se superpose au registre EAX, qui lui-même se superpose au registre AX, qui se superpose au registre AL, et pareil pour RBX, RCX et RDX pour l'exemple. Les registres YMMx sont longs de 256 bits, soient 32 octets. On peut donc y mettre 4 double, ce qui divise nos opérations par 4. Je n'ai pas fait le code qui s'occupe des variables non alignées, ni celui qui gère les vecteurs d'une taille autre qu'un multiple de 4. Notez également que les instructions de calcul proprement dites prennent 3 opérandes : les deux opérandes habituels, plus, en tout premier, l'opérande de destination.
Comme nous aurons besoin du produit scalaire pour faire le produit matriciel, aussi nous en occupons-nous dès maintenant :
PUBLIC dotProduct_asm
dotProduct_asm PROC
vxorpd ymm1, ymm1, ymm1
;Nombre d'éléments à sommer mis dans RCX parce que c'est le registre compteur et accessoirement le premier paramètre,
shr rcx, 2 ;qu'on divise par 4, parce qu'on va les sommer par 4
dot:
vmovapd ymm0, YMMWORD PTR [r8];On met dans un registre du processeur à virgule flottante 4 double
vfmadd231pd ymm1, ymm0, YMMWORD PTR [rdx]
add rdx, 32 ;On passe aux 4 double suivants
add r8, 32 ;
loop dot ;Et on boucle sur RCX
vpermpd ymm0, ymm1, 01001110b
vaddpd ymm2, ymm1, ymm0 ;L'instruction de la somme
vpermpd ymm0, ymm1, 01001011b
vaddpd ymm2, ymm2, ymm0 ;L'instruction de la somme
vpermpd ymm0, ymm1, 01001001b
vaddpd ymm0, ymm2, ymm0 ;L'instruction de la somme
ret
dotProduct_asm ENDP
VXORPD pour mettre le registre YMM1 à 0. Notons que lui aussi est passé à 3 paramètres.
SHR pour diviser par une puissance de 2, en l'occurence 4.
VMOVAPD pour charger le premier opérande en mémoire.
VFMADD231PD pour la magie du produit scalaire. Cette instruction fait partie d'une famille d'instructions qui font une multiplication et une somme. Celle-ci multiplie les paramètres 2 et 3 et ajoute le résultat au paramètre 1. Le résultat est ensuite stocké dans le paramètre 1.
Il faut ensuite additionner les 4 double résultant du "produit scalaire", chose qui est faite ici par des permutations.
Ils ne sont pas bien folichons par rapport au code généré par Visual Studio C++, il faut bien le dire. Cependant des questions restent en suspens. Par exemple, un des codes générés par le compilateur est moins rapide quand je l'utilise en lieu et place de ma fonction.